按照微软教程安装即可:
https://docs.microsoft.com/zh-cn/learn/paths/go-first-steps/
踩坑
- 国内下载Go链接:
- VS Code 安装 Go插件失败解决:
1 | $ go env -w GO111MODULE=on //开启mod |
按照微软教程安装即可:
https://docs.microsoft.com/zh-cn/learn/paths/go-first-steps/
踩坑
1 | $ go env -w GO111MODULE=on //开启mod |
Store and organize SQL
Faster execution
Data security
1 | DELIMITER $$ |
DELIMITER 重定义分隔符, 也就是将新分隔符包含的内容视为一个unit, 而不是将”;”结束的一个个语句视为unit.
调用存储过程:
1 | CALL get_clients() |
1 | DROP PROCEDURE IF EXISTS get_clients; |
创建存储过程的基本框架
1 | DROP PROCEDURE IF EXISTS get_clients; |
1 | DROP PROCEDURE IF EXISTS get_clients_by_state; |
调用:
1 | CALL get_clients_by_state('CA') |
1 | DROP PROCEDURE IF EXISTS get_clients_by_state; |
调用:
1 | CALL get_clients_by_state(NULL) |
IF-ELSE
1 | DROP PROCEDURE IF EXISTS get_clients_by_state; |
更简洁的写法:
1 | DROP PROCEDURE IF EXISTS get_clients_by_state; |
IFNULL(state, c.state) 如果 state = NULL,则返回 c.state,而 c.state = c.state 永远为 TRUE
1 | DROP PROCEDURE IF EXISTS make_payment; |
1 | DROP PROCEDURE IF EXISTS get_unpaid_invoices_for_client; |
调用:
1 | set @invoices_count = 0; |
1 | -- User or session variables |
Demo
1 | DROP PROCEDURE IF EXISTS get_risk_factor; |
函数:只能返回单一值
存储过程:可以返回拥有多行多列的结果集👉 函数属性
- DETERMINISTIC: 一样的输入总是会返回一样的输出
- READS SQL DATA: 函数中有读sql数据的内容
- MODIFIES SQL DATA:函数中有修改sql数据的内容
1 | DROP FUNCTION IF EXISTS get_risk_factor_for_client; |
使用函数:
1 | SELECT |
Trigger: A block of SQL code that automatically gets executed before or after an insert, update or delete statement.
To enhance data consistency
1 | DELIMITER $$ |
可以触发除了 payments 之外的任何表的更新。NEW表示新 insert 的 payment (amount是payments 表的 column)。如果是DELETE,就用 OLD 表示删除的行。
1 | SHOW TRIGGERS LIKE 'payments%' -- show filtered triggers |
1 | DROP TRIGGER IF EXISTS payments_after_insert |
使用触发器进行记录
首先建立审计表:
1 | USE sql_invoicing; |
假如有这两个触发器:
1 | DROP TRIGGER IF EXISTS payments_after_insert; |
1 | DROP TRIGGER IF EXISTS payments_after_delete; |
然后触发事件发生:
1 | INSERT INTO payments |
1 | DELETE FROM payments |
刷新审计表可以看到:
| client_id | date | amount | action_type | action_date |
|---|---|---|---|---|
| 5 | 2019-01-01 | 10.00 | Insert | 2021-05-20 19:12:31 |
| 5 | 2019-01-01 | 10.00 | Delete | 2021-05-20 19:13:31 |
Event: A task (or block of SQL code) that gets executed according to a schedule.
1 | SHOW VARIABLES LIKE 'event%' -- 查看命名中有event的变量 |
1 | SET GLOBAL event_scheduler = OFF -- 关掉它 |
Demo
1 | DELIMITER $$ |
查看事件
1 | SHOW EVENTS LIKE 'yearly%'; |
删除事件
1 | DROP EVENT IF EXISTS yearly_delete_stale_audit_rows; |
更改事件
ALTER EVENT:跟 CREATE EVENT 语法一样。
可以用来展示启用/禁用事件:
1 | ALTER EVENT yearly_delete_stale_audit_rows ENABLE |
1 | ALTER EVENT yearly_delete_stale_audit_rows DISABLE |
1 | USE sql_invoicing; |
可以在”Views”看到这个视图.可以像使用table一样用视图.
删除视图
1 | DROP VIEW sales_by_client |
更改视图
1 | USE sql_invoicing; |
如果视图中没有:
DISTINCT
Aggregate Functions (MIN, MAX, SUM)
GROUP BY / HAVING
UNION
就是可更新视图,就可以增删改:
比如:
1 | CREATE OR REPLACE VIEW invoices_with_balance AS |
invoices_with_balance 就是可更新视图,可以增删改:
1 | DELETE FROM invoices_with_balance |
1 | UPDATE invoices_with_balance |
上例中,进行如下更改:
1 | UPDATE invoices_with_balance |
该视图中 invoice_id = 2 的行消失了(因为不再满足(invoice_total - payment_total) > 0的条件)
如果不想 UPDATE 或 DELETE 语句使得某些行从视图中删除, 就这样:
1 | CREATE OR REPLACE VIEW invoices_with_balance AS |
后面再执行这样的:
1 | UPDATE invoices_with_balance |
就会报错:
Error Code: 1369. CHECK OPTION failed
Simplify queries
Reduce the impact of changes
Restrict access to the data
1 | SELECT ROUND(5.7355, 2) -- 保留小数点后2位, 四舍五入: 5.74 |
1 | SELECT LENGTH('sky') -- 3 |
1 | SELECT LTRIM(' Sky') -- 去除左边的空格:Sky |
子串
1 | SELECT LEFT('Kindergarten', 4) -- Kind |
查找位置
1 | SELECT LOCATE('N', 'Kindergarten') -- 3 不区分大小写,若不在字符串中则返回0 |
替换
1 | SELECT REPLACE('Kindergarten', 'garten', 'garden') -- Kindergarden |
拼接
1 | SELECT CONCAT('first', 'last') -- firstlast |
1 | USE sql_store; |
1 | SELECT NOW(), CURDATE(), CURTIME() |
| NOW() | CURDATE() | CURTIME() |
|---|---|---|
| 2021-05-19 19:08:56 | 2021-05-19 | 19:08:56 |
获取指定的时间构成元素
1 | SELECT YEAR(NOW()) -- 2021 |
获取时间的字符串
1 | SELECT DAYNAME(NOW()), MONTHNAME(NOW()) |
| DAYNAME(NOW()) | MONTHNAME(NOW()) |
|---|---|
| Wednesday | May |
EXTRACT
1 | SELECT EXTRACT(DAY FROM NOW()) -- 19 |
1 | SELECT DATE_FORMAT(NOW(), '%M %d %Y') |
May 19 2021
1 | SELECT DATE_FORMAT(NOW(), '%H:%i %p') |
19:17 PM
1 | SELECT DATE_ADD(NOW(), INTERVAL 1 DAY) -- 2021-05-20 19:21:32 |
1 | SELECT DATEDIFF('2021-01-05', '2021-01-01') -- 4 |
1 | SELECT TIME_TO_SEC('09:00') - TIME_TO_SEC('09:02') -- -120 (单位:秒) |
IFNULL
1 | USE sql_store; |
IFNULL(shipper_id, ‘Not assigned’) 即如果shipper_id为NULL, 就改为’Not assigned’
输出:
| order_id | shipper |
|---|---|
| 1 | Not assigned |
| 3 | Not assigned |
| 8 | Not assigned |
| 9 | 1 |
| 2 | 4 |
COALESCE
1 | USE sql_store; |
如果shipper_id为空,就返回comments中的值,如果comments也为空,则返回’Not assigned’.
格式:
IF(expression, first, second)
如果expression为真,返回first, 为假则返回second
1 | SELECT |
当前年份为2021, 所以2019的为’Active’ (Mosh制作视频时为2019), 其他都是’Archived’:
| order_id | order_date | category |
|---|---|---|
| 1 | 2019-01-30 | Active |
| 2 | 2018-08-02 | Archived |
| 3 | 2017-12-01 | Archived |
| 4 | 2017-01-22 | Archived |
| 5 | 2017-08-25 | Archived |
1 | SELECT |
输出:
| order_id | category |
|---|---|
| 1 | Active |
| 2 | Last Year |
| 3 | Archived |
| 4 | Archived |
| 5 | Archived |
| 6 | Last Year |
| 7 | Last Year |
| 8 | Last Year |
| 9 | Archived |
| 10 | Last Year |
1 | -- Find products that are more |
1 | -- Find the products that have never been ordered |
1 | -- Find clients without invoices |
用连接的方法:
1 | SELECT * |
在时间一样的情况下, 选择更易读的那种方法
1 | -- Select invoices larger than all invoices of client 3 |
改用all 关键字:
1 | SELECT * |
1 | -- Select clients with at least two invoices |
改用any 关键字
1 | -- Select clients with at least two invoices |
即 “IN” 相当于 “=ANY”
1 | -- Select employees whose salary is |
注意到子查询用到了外查询的 e.office_id, 也就是说子查询和外查询是相关子查询.
对于非相关子查询, 执行一次就可以了.
但是对于相关子查询, 外查询每一条record都要执行一次子查询,所以执行时间相对较长.
1 | -- Select clients that have an invoice |
子查询返回一个列表, 然后外查询看在不在此列表中.如果子查询返回的列表非常大,就会很影响性能.
使用EXISTS运算符
1 | -- Select clients that have an invoice |
对于外查询的每一条record, EXISTS 子查询返回TRUE / FALSE, 若返回TRUE,就添加到结果集中.
Exercise
1 | -- Find the products that have never been ordered |
1 | SELECT |
得到这样一张表:
| invoice_id | invoice_total | invoice_average | difference |
|---|---|---|---|
| 1 | 101.79 | 152.388235 | -50.598235 |
| 2 | 175.32 | 152.388235 | 22.931765 |
| 3 | 147.99 | 152.388235 | -4.398235 |
| 4 | 152.21 | 152.388235 | -0.178235 |
| 5 | 169.36 | 152.388235 | 16.971765 |
| 6 | 157.78 | 152.388235 | 5.391765 |
| 7 | 133.87 | 152.388235 | -18.518235 |
Exercise
得到这样一张表:
| client_id | name | total_sales | average | difference |
|---|---|---|---|---|
| 1 | Vinte | 802.89 | 152.388235 | 650.501765 |
| 2 | Myworks | 101.79 | 152.388235 | -50.598235 |
| 3 | Yadel | 705.90 | 152.388235 | 553.511765 |
| 4 | Kwideo | 152.388235 | ||
| 5 | Topiclounge | 980.02 | 152.388235 | 827.631765 |
Solution:
1 | SELECT |
将上面的查询结果当成表来用,放在FROM 子句中:
1 | SELECT * |
得到:
| client_id | name | total_sales | average | difference |
|---|---|---|---|---|
| 1 | Vinte | 802.89 | 152.388235 | 650.501765 |
| 2 | Myworks | 101.79 | 152.388235 | -50.598235 |
| 3 | Yadel | 705.90 | 152.388235 | 553.511765 |
| 5 | Topiclounge | 980.02 | 152.388235 | 827.631765 |
1 | SELECT |
Exercise
1 | SELECT |
| date_range | total_sales | total_payments | what_we_expect |
|---|---|---|---|
| First half of 2019 | 1539.07 | 212.97 | 1326.1 |
| Second half of 2019 | 1051.53 | 148.41 | 903.12 |
| Total | 2590.6 | 361.38 | 2229.22 |
Demo 1
1 | SELECT |
⚠ 各个子句的顺序不能错,比如不能将WHERE移到ORDER BY 下面
得出每个client在2019年下半年的订单总金额
| client_id | total_sales |
|---|---|
| 5 | 489.52 |
| 3 | 427.54 |
| 1 | 134.47 |
Demo 2
1 | SELECT |
得到每个(state, city)组合的总金额:
| state | city | total_sales |
|---|---|---|
| NY | Syracuse | 802.89 |
| WV | Huntington | 101.79 |
| CA | San Francisco | 705.90 |
| OR | Portland | 980.02 |
Exercise
1 | SELECT |
根据交易日期和交易方式求总金额。
| date | payment_method | total_payments |
|---|---|---|
| 2019-01-03 | Credit Card | 74.55 |
| 2019-01-08 | Credit Card | 32.77 |
| 2019-01-08 | Cash | 10.00 |
| 2019-01-11 | Credit Card | 0.03 |
| 2019-01-15 | Credit Card | 148.41 |
| 2019-01-26 | Credit Card | 87.44 |
| 2019-02-12 | Credit Card | 8.18 |
👉 使用WHERE子句可以在行分组之前过滤数据
👉 使用HAVING子句可以在行分组之后过滤数据
1 | SELECT |
| client_id | total_sales |
|---|---|
| 1 | 802.89 |
| 3 | 705.90 |
| 5 | 980.02 |
复合搜索条件
1 | SELECT |
获取金额超过500并且多于5个订单的client的结果
| client_id | total_sales | number_of_invoices |
|---|---|---|
| 5 | 980.02 | 6 |
Exercise
1 | -- Get the customers located in VG |
| customer_id | first_name | last_name | state | total_sales |
|---|---|---|---|---|
| 2 | Ines | Brushfield | VA | 157.92 |
Demo 1
1 | SELECT |
WITH ROLLUP 自动计算总数
| client_id | total_sales |
|---|---|
| 1 | 802.89 |
| 2 | 101.79 |
| 3 | 705.90 |
| 5 | 980.02 |
| 2590.60 |
Demo 2
1 | SELECT |
注意: GROUP BY 子句中由于使用了 WITH ROLLUP, 就不能使用别名 payment_method
得到每个组及整个结果集的汇总集:
| date | payment_method | total_payments |
|---|---|---|
| 2019-01-03 | Credit Card | 74.55 |
| 2019-01-03 | 74.55 | |
| 2019-01-08 | Cash | 10.00 |
| 2019-01-08 | Credit Card | 32.77 |
| 2019-01-08 | 42.77 | |
| 2019-01-11 | Credit Card | 0.03 |
| 2019-01-11 | 0.03 | |
| 2019-01-15 | Credit Card | 148.41 |
| 2019-01-15 | 148.41 | |
| 2019-01-26 | Credit Card | 87.44 |
| 2019-01-26 | 87.44 | |
| 2019-02-12 | Credit Card | 8.18 |
| 2019-02-12 | 8.18 | |
| 361.38 |
注意到 2019-01-08 对 Cash 和 Credit Card 有一个汇总值.
Data type
👉 VARCHAR: 可变长度字符串(节省空间)
👉 CHAR: 字符串,不满指定长度就会填充满Properties
👉 PK: Primary Key
👉 NN: Not Null
👉 AI: Automatic Increment
1 | INSERT INTO customers |
有些不是必填的, 可以skip掉:
Another Way
1 | INSERT INTO customers ( |
1 | INSERT INTO shippers (name) |
order_items是orders的子表, 列出更为详细的信息.在orders插入行, 相应的在order_items也要插入行:
1 | INSERT INTO orders (customer_id, order_date, status) |
LAST_INSERT_ID()相当于一个method/function, 直接调用获取最近插入的record的id.
1 | CREATE TABLE orders_archived AS |
通过这种方式创建的表复制会没有PK, AI这些属性
上例中的SELECT * FROM orders是子查询.
INSERT INTO也可以用子查询:
1 | INSERT INTO orders_archived |
orders_archived表中只有满足条件的records.
1 | UPDATE invoices |
1 | UPDATE invoices |
1 | UPDATE invoices |
在MySQL workbench需要取消safe update选项才能更新多行.
1 | UPDATE invoices |
client_id=3对应有多项record, 都会被update
将上例改为:
1 | UPDATE invoices |
如果子查询返回的是多个client_id:
1 | UPDATE invoices |
⚠ 在执行查询之前, 应该先执行子查询看看对不对.
根据条件删除某些行
1 | DELETE FROM invoices_archived |
子查询
1 | DELETE FROM invoices |
删除整表所有records
1 | DELETE FROM invoices_archived |
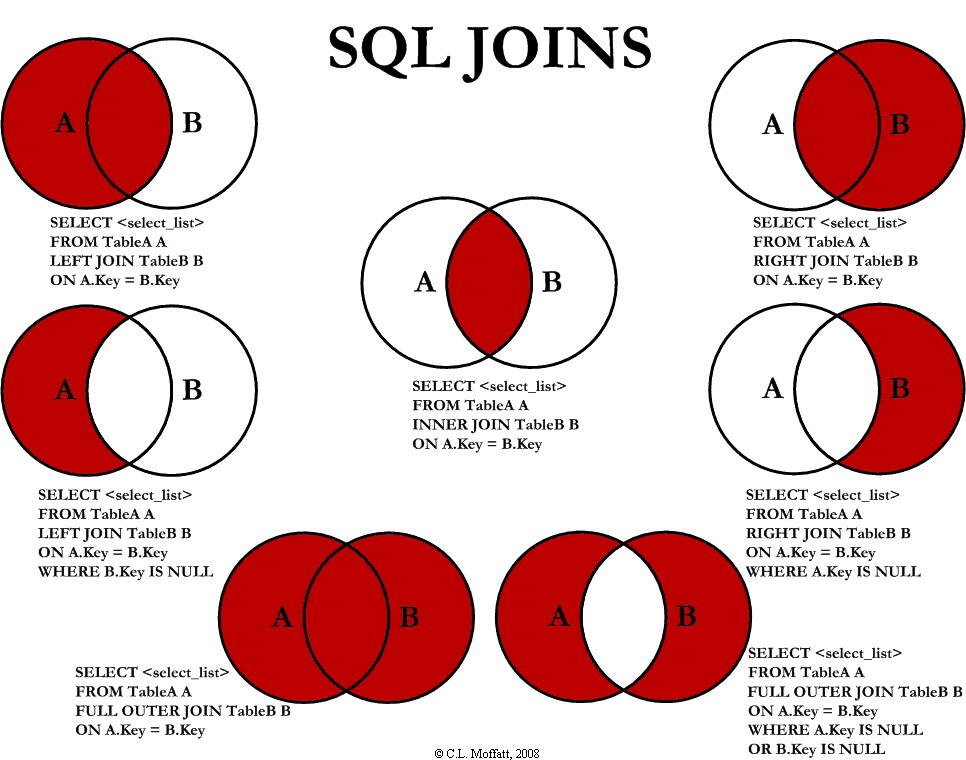
1 | SELECT order_id, o.customer_id, first_name, last_name |
返回表orders在表customers中有对应record的项
o和c分别是orders和customers的别名,以简化代码
关键字INNER可省略
1 | USE sql_store; -- 选择了数据库sql_store为当前数据库 |
将表和自己连接,但是给不同的别名以区分。如下,manager也是一名员工,其信息也在表employees中,用自连接可以得到employee和TA的manager的具体员工信息。
1 | USE sql_hr; -- 选择了数据库sql_hr为当前数据库 |
1 | USE sql_store; |
表orders先和表customers连接,然后与表order_statuses连接。
对于有两个主键的表,要用两个主键作为条件与别的表连接。例如表order_items的主键是order_id和product_id
1 | SELECT * |
1 | SELECT * |
不建议使用隐式连接语法,要是忘写WHERE就完了。
1 | SELECT |
LEFT (OUTER) JOIN 和 RIGHT (OUTER) JOIN, OUTER 可省略
1 | SELECT |
1 | USE sql_hr; |
使用于两张表的键名完全一致的情况
1 | SELECT |
1 | SELECT * |
自动找到同名的column来连接。(容易出错,不建议使用)
1 | SELECT |
连接两张表的所有records
1 | SELECT |
应用场景:表一是大中小型号,表二是红黄蓝等各种颜色,将所有型号和所有颜色组合起来。
隐式语法
1 | SELECT |
筛选某些records,用union将多次筛选的结果联合起来
1 | SELECT |
也可以联合多张表
1 | SELECT first_name -- 决定列名 |
练习
根据积分将顾客划分为金银铜三档:
1 | SELECT |
从一张表(customers)中选取某些列
1 | SELECT |
1 | SELECT DISTINCT state -- DISTINCT 只保留重复项中的一项 |
过滤作用,根据条件选择records
(各个WHERE子句只是提供不同的示例,运行时选择一个WHERE子句,其余注释掉,下文同)
1 | SELECT * |
运算符有:
1 | > |
1 | SELECT * |
AND优先级高于OR
1 | SELECT * |
1 | SELECT * |
1 | -- 也可用于非数值 |
1 | -- 字符串模式匹配 |
1 | /***SUMMARY**/ |
1 | -- regular expression (REGEXP) 正则表达式 |
1 | ^ beginning |
1 | SELECT * |
默认是按照主键(primary key)排序,使用ORDER BY 子句可以指定排序的键
1 | SELECT * |
1 | SELECT * |
1 | -- birth_date不在选出来的列里,still work |
1 | SELECT * |