任务:从输入的视频中直接预测raw声音信号
方法:编码-解码架构,即视频编码器+音频生成器(分层RNN)
建模:条件生成问题。训练一个有条件的生成模型以从输入的视频中合成raw声音波形。
估计条件概率:
$x_{1},x_{2},…,x_{m}$是输入视频帧的表示;$y_{1},y_{2},…,y_{n}$是输出声音波形的值(取值为0~255的整数序列)。原始波形样本是范围从-1到1的实数值,文中重新缩放和线性量化它们到256个bins。通常$m<<n$,因为音频的采样率远高于视频的采样率。
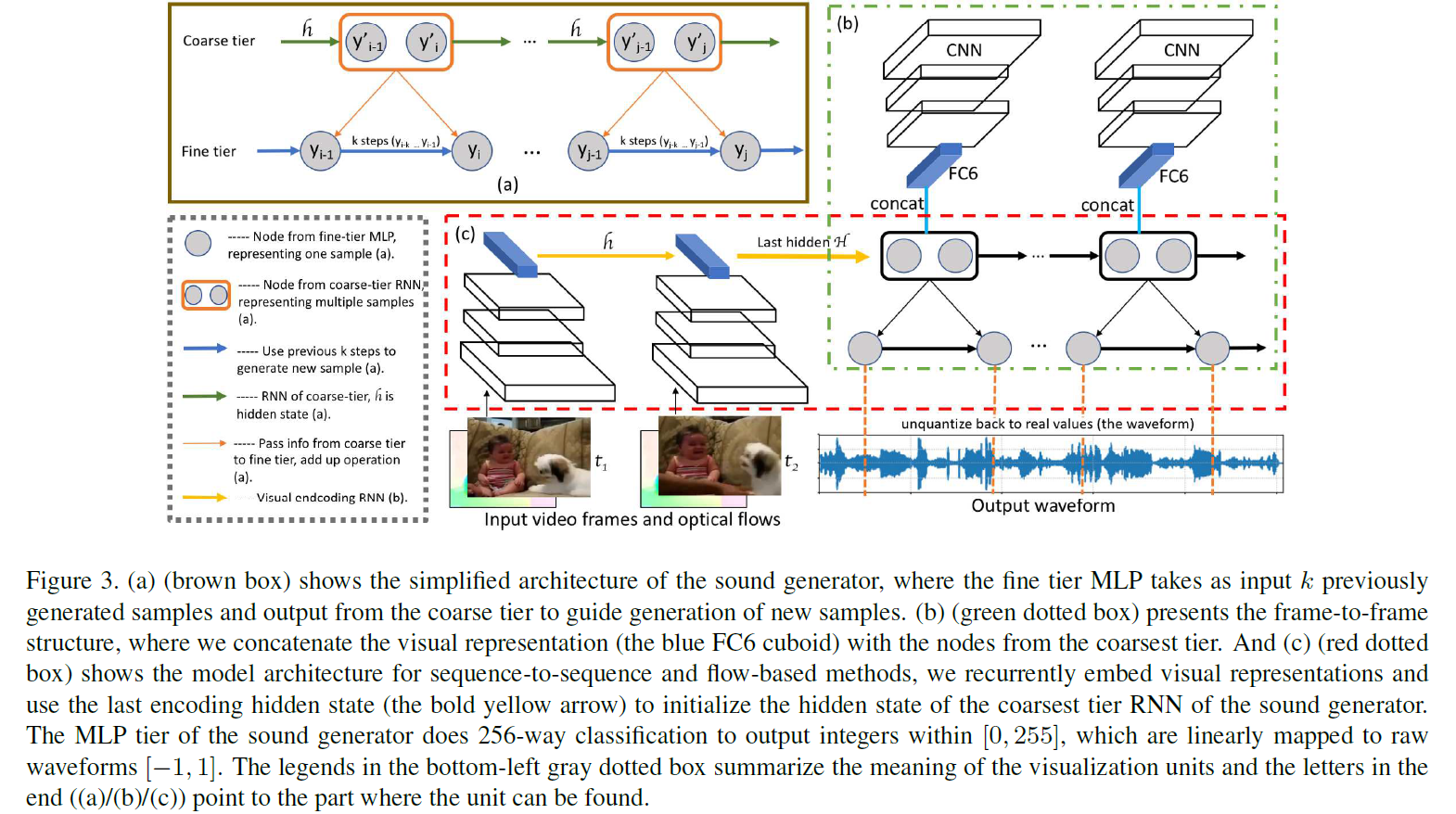
Sound Generator
采用的采样频率为:16kHz
问题:序列长度很长
解决方法:选用SampleRNN为声音生成器(原因:其从粗到细的结构使模型能够生成非常长的序列,每一层的循环结构捕捉到遥远样本之间的依赖关系。)
具体:1)细节层是多层感知机(MLP),获取下一个粗糙层(上层)的输出和前面的$k$个样本,以生成一个新样本。在训练过程中,波形样本(实数值,从-1到1)被线性量化到从0到255的整数范围,可以将最细的层的MLP看成是256-类分类器,在每个timestep预测得到一个样本(然后映射回实值,获得最终波形)。
2)粗糙层可以是GRU, LSTM或其他的RNN变体。包含多个波形样本(图中为2个)的节点意味着该层基于前一个timestep以及更粗层的预测,在每个timestep共同预测多个样本。
Video Encoder
Frame-to-frame method
$f_{i}$和$x_{i}$分别是视频的第$i$帧和该帧的表征。$V(.)$是在ImageNet上预先训练的VGG19网络的fc6特征提取操作,$x_{i}$是一个4096维的向量。在该模型中,将帧表征与声音生成器最粗层RNN的节点(样本)统一连接,对视觉信息进行编码,如图3(b)所示(内容以绿色虚线框表示)。
视频与音频采样率不同的问题解决:对于每个$x_{i}$,重复$s$次,其中
只将视觉特征提供给SampleRNN的最粗糙层,因为这一层很重要,因为它指导所有更细的层的生成以及提高计算效率。
Sequence-to-sequence method
提取VGG19网络的fc6特征作为每一帧的表征,然后用RNN处理作为视频编码器,使用视频编码器的最后一个隐藏状态初始化声音发生器的最粗层RNN的隐藏状态,然后开始声音生成。此时声音生成任务变为:
$H$表示视频编码RNN的最后一个隐藏状态或等效的声音发生器最粗糙层RNN的初始隐藏状态。
视频与音频采样率不同的问题解决:不像上面提到的基于帧的模型中明确地强制视频帧和波形样本之间的对齐。在这个序列到序列模型中,我们期望模型通过编码和解码来学习这两种模式之间的对齐。
Flow-based method
Motiv:视觉领域的运动信号,虽然有时很微小,但对于合成真实且同步良好的声音是至关重要的。
方案:增加一个基于光流的深度特征以明确捕获运动信号。与序列到序列方法不同之处为
$o_{i}$是第$i$帧的光流,$F(.)$是提取基于光流的深度特征的函数(非学习得到)。
Visual to Sound: Generating Natural Sound for Videos in the Wild