Sound Representation
计算声音特征的方法:将声波$w(t)$分解为子带包络$s_{n}(t)$(将声波滤波然后应用非线性)。1)在等效矩形带宽(ERB)尺度上应用40个带通滤波器$f_{n}$(加上一个低通和高通滤波器),并取响应的希尔伯特包络线;2)将包络下采到90Hz(约为3样本/帧)并压缩。
$H$是希尔伯特变换,$D$表示下采样,压缩常数$c=0.3$。由此产生的表示被称为耳蜗图(cochleagram)。
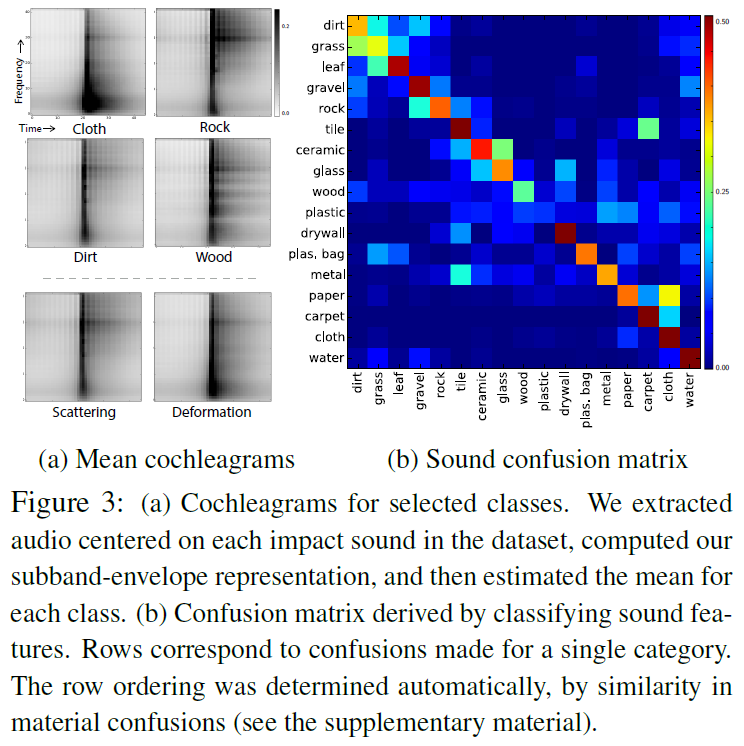
一般来说,撞击声如何捕捉材料的属性?为了从经验上评测这一点,文章使用子带包络作为特征向量,训练了一个线性支持向量机来预测数据库中的声音由哪个材料发出。文章对训练集重新采样,使每个类包含相同数量的撞击声(每类260个)。最终得到的材料分类器具有45.8% (chance = 5.9%)的分类平均精度(即每类精度值的平均值),其混淆矩阵如图3(b)所示。这些结果表明,撞击声传达了有关材料的重要信息,因此,如果一个算法能够学习从图像中准确预测这些声音,它就会有关于材料类别的隐含知识。
Predicting visually indicated sounds
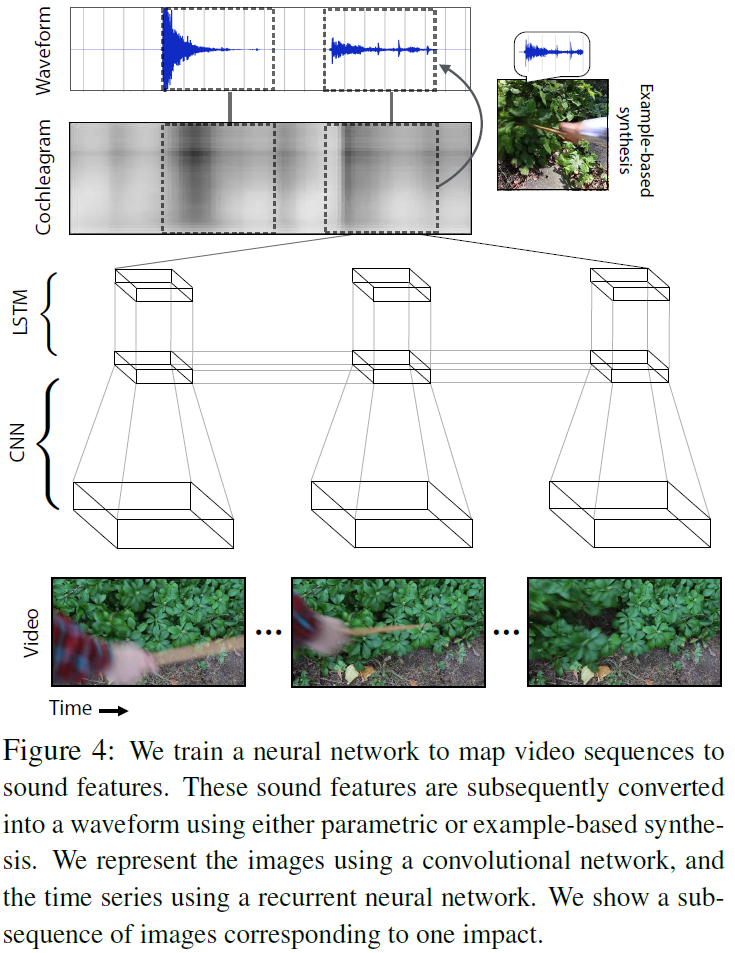
将此任务建模为一个回归问题,目标是将一个视频帧序列映射为一个声频特征序列。使用的模型是RNN,以颜色和运动(motion)信息作为输入,预测出声频波形的子带包络。最后,从声音特征中产生波形。
Regressing sound features
输入图像序列:$I_{1}, I_{2}, …, I_{N}$
输出声音特征序列:$\mathop{s_{1}}\limits ^{\rightarrow}, \mathop{s_{2}}\limits ^{\rightarrow}, \mathop{s_{T}}\limits ^{\rightarrow}, where \mathop{s_{t}}\limits ^{\rightarrow}\in \mathbb{R}^{42}$
这些声音特征对应于图4中所示的耳蜗块。文章使用循环神经网络(RNN)来解决这个回归问题,它将卷积神经网络(CNN)计算的图像特征作为输入。
图像表示:如何表示运动(motion)信息?计算每一帧的spacetime图像,即三个通道是上一帧、当前帧和下一帧灰度版本的图像。对于每一帧$t$,通过拼接帧$t$的spacetime图像和第1帧的颜色图像的CNN特征来构建输入特征向量$x_{t}$,即
文章中训练的两种方式:1)从零开始初始化CNN,然后和RNN一起训练它;2)用一个为ImageNet分类训练的网络的权值初始化CNN。当使用预训练时,从卷积层中预计算特征,并仅对完全连接的层进行微调。
声音预测模型:使用基于LSTM的RNN模型。为了补偿视频和音频采样率之间的差异,文章中复制每个CNN特征向量$k$次(文章中使用$k=3$)
由此得到与声音特征序列等长的CNN特征序列$x_{1}, x_{2}, …, x_{N}$。在RNN的每个timestep,文章中使用当前图像特征向量$x_{t}$来更新隐藏变量$h_{t}$,然后通过一个仿射变换得到声音特征。为了使学习问题更简单,文中使用PCA在每个时间步长的42维特征向量投影到10维空间,然后预测这个低维向量。对网络进行评估时,反求PCA变换以获得声音特征。
文章使用随机梯度下降以Caffe共同训练RNN和CNN。它有助于收敛去除dropout和剪辑大的梯度。当从头开始训练时,文中通过对视频进行裁剪和镜像转换来增强数据。文中也使用多个LSTM层(数量取决于任务)。
Generating a waveform
问题:如何从声音特征中产生声波?
- 简单参数综合法:迭代地将子带包络加到白噪声样本上(文中只使用了一次迭代)。这种方法对于检查音频特征所捕获的信息非常有用,因为它代表了从特征到声音的直接转换。
- 对于产生对于人耳似是而非的声音的任务,在从特征到波形的转换过程中,先施加一个强的自然声音是更有效的。因此使用基于实例的合成方法,该方法将声音特征的窗口捕捉到训练集中最接近的样本上。文中通过拼接预测的声音特征$\mathop{s_{1}}\limits ^{\rightarrow}, \mathop{s_{2}}\limits ^{\rightarrow}, …, \mathop{s_{T}}\limits ^{\rightarrow}$(或它们的一个子序列)形成一个查询向量,在$L_{1}$距离测量的训练集中寻找其最近的邻居,并传递相应的波形。