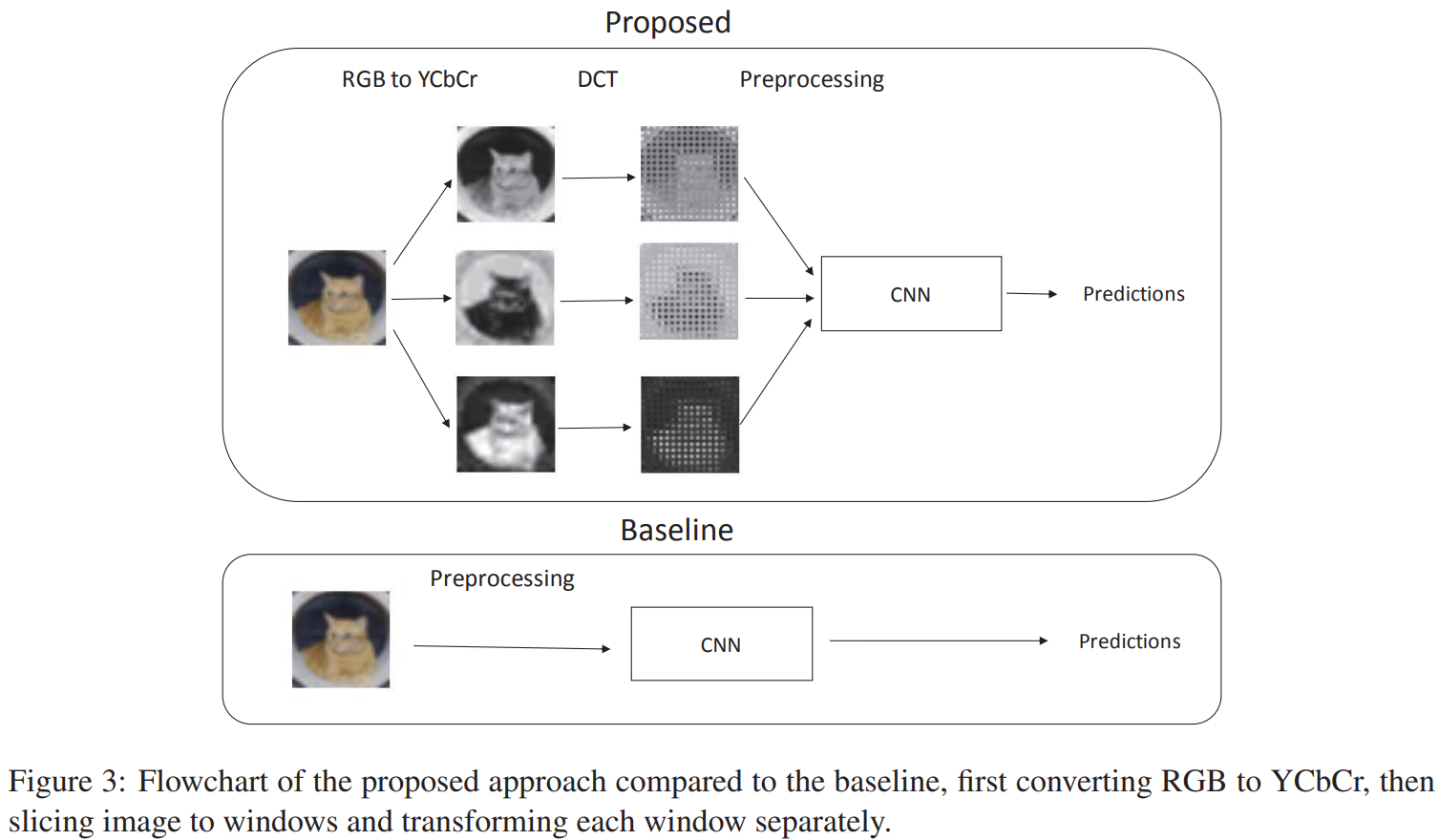
Faster Neural Networks Straight from JPEG
Motivation
1、缩短图像解码时间。大部分图片都是通过JPEG格式进行存储,JPEG格式转换为RGB需要解码。而如果通过频域学习,解码时只需要从霍夫曼编码中获取DCT系数即可,不需要完全解码得到RGB图像;
2、让模型更高效。CNN模型的优势是表达能力强(参数很多),所需先验少。但是先验少,所以需要大量参数,使得CNN模型中存在大量冗余计算。频域学习其实是一个先验,如果数据分布和该先验一致,那么达到同样的效果,模型可以更简单,所需要的训练数据可以更少。
Method
Evaluation
在ImageNet上实验。目标是准确率高且运行速度快。
Baseline
Vanilla ResNet-50, 输入为RGB图像。Top-5错误率7.4%左右,速度200 image/s:
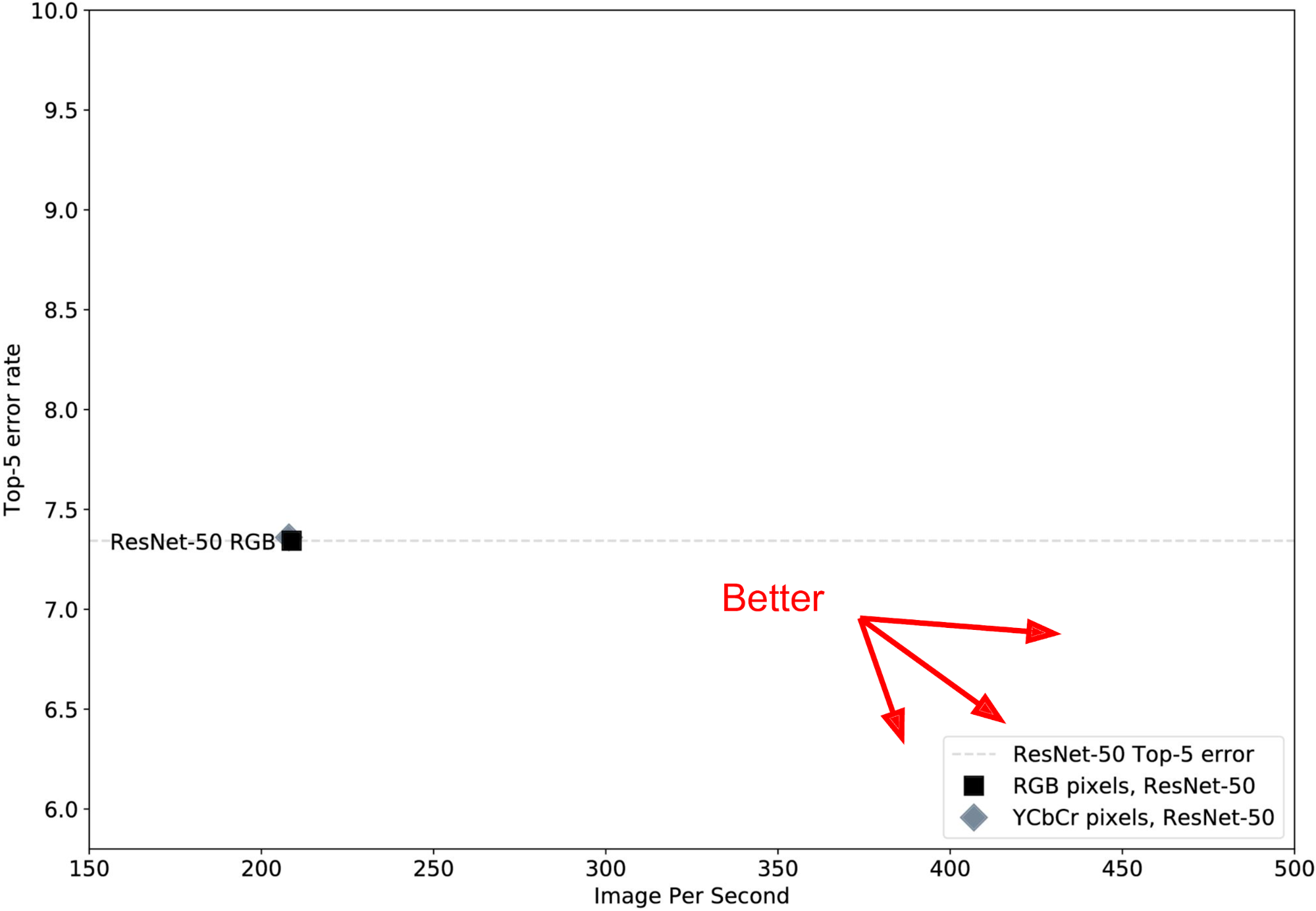
以YCbCr为输入,效果与RGB差不多。期望的效果是在图中往右下发展(右:速度快;下:错误率低)。
希望运行速度更快:1)shorter ResNet-50 (减少网络层数);2)thinner ResNet-50 (减少每层的通道数)
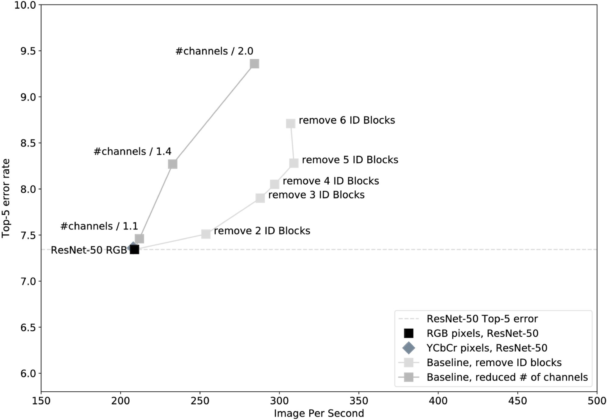
结论:shorter ResNet-50优于thinner ResNet-50。浅灰色的“Remove N ID Blocks”的线形成了帕累托前沿(Pareto front),显示了“non-dominated”网络的集合,或者是那些在速度和准确性之间做出最佳权衡的网络。
Training networks on DCT inputs
问题1:针对不同的输入尺寸如何处理?
RGB图像大小:(224, 224, 3)
DCT系数: 1) Y-(28, 28, 64);
2) Cb/Cr-(14, 14, 64)
解决:在进入网络之前combine Y和Cb、Cr
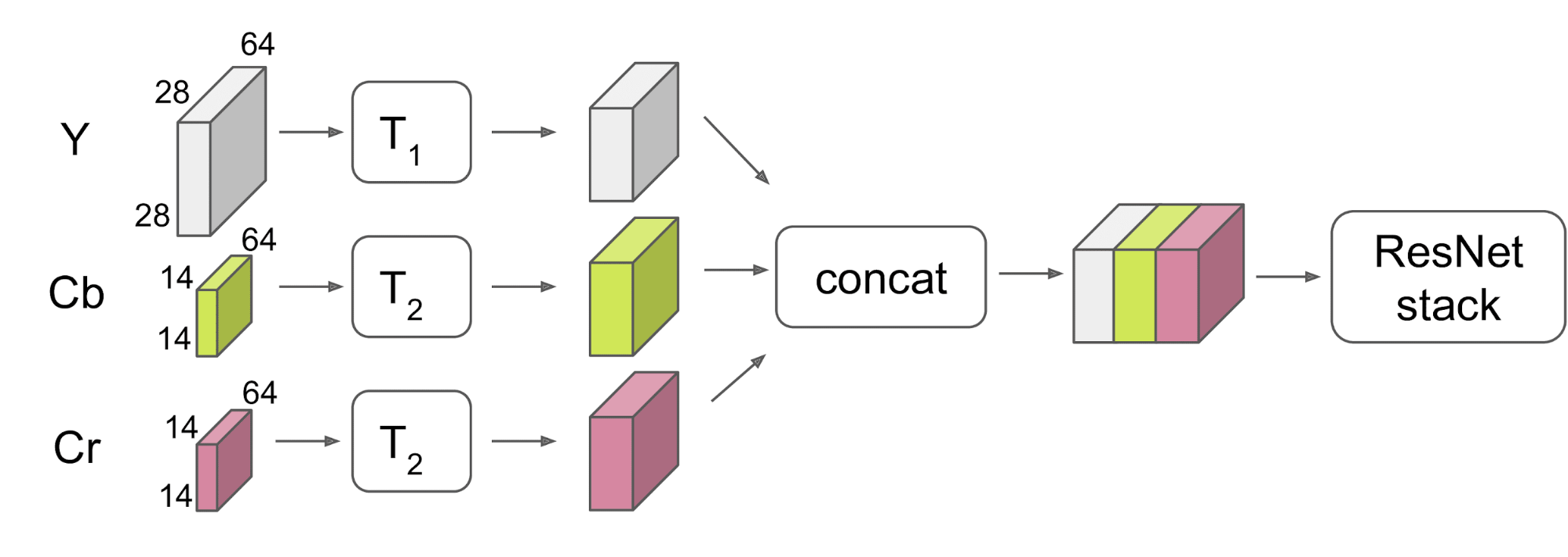
1. DCT Early Merge architectures:1)下采Y(“DownSampling”);2)上采Cb、Cr(“UpSampling”)
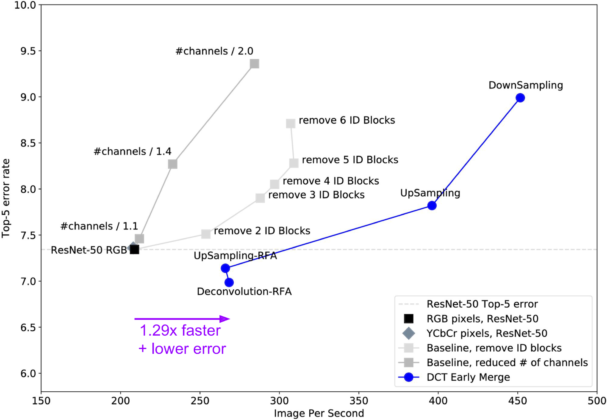
结论: 1)DownSampling:fast (450 image/s) but high error;
2) UpSampling:slower but lower error;
问题2:UpSampling的错误率比baseline高
可能的原因:感受野过大。传到baseline ResNet-50的中间层时感受野约为70像素;而UpSampling模型的相应感受野达到了110像素。这是因为DCT输入层的[stride, receptive field]是[8, 8],而经典输入层该值为 [1, 1]。 直观地说,要求网络学习110px宽的感受野,但没有给它足够的层或计算能力来做到这一点。
解决:创造了一个Receptive Field Aware (RFA) 模型→UpSampling-RFA。做法是给神经网络的前层增加额外的步长1模块。此时逐层的感受野增长变得更平滑,近似与baseline ResNet-50相匹配。
如果UpSampling通过可学反卷积而非像素复制得到,则错误率可以进一步降低,达到目前为止最好的模型:Deconvolution-RFA(错误率6.98%;加速1.29倍)。
效果:沿着DCT Early Merge线的其他模型现在形成了新的帕累托前沿,在误差和速度的权衡方面超越了以前的模型。
2. DCT Late Merge architectures
实验发现允许亮度分支多层计算才能获得较高的准确率,而色度路径可以在较少的计算层数下不损害准确率。换句话说,1) 将Y通道放到网络的前面,而Cb/Cr信息在中途注入,其效果与 2) 从前面开始全部三个通道的运算 一样好,而方法1)节省了计算。
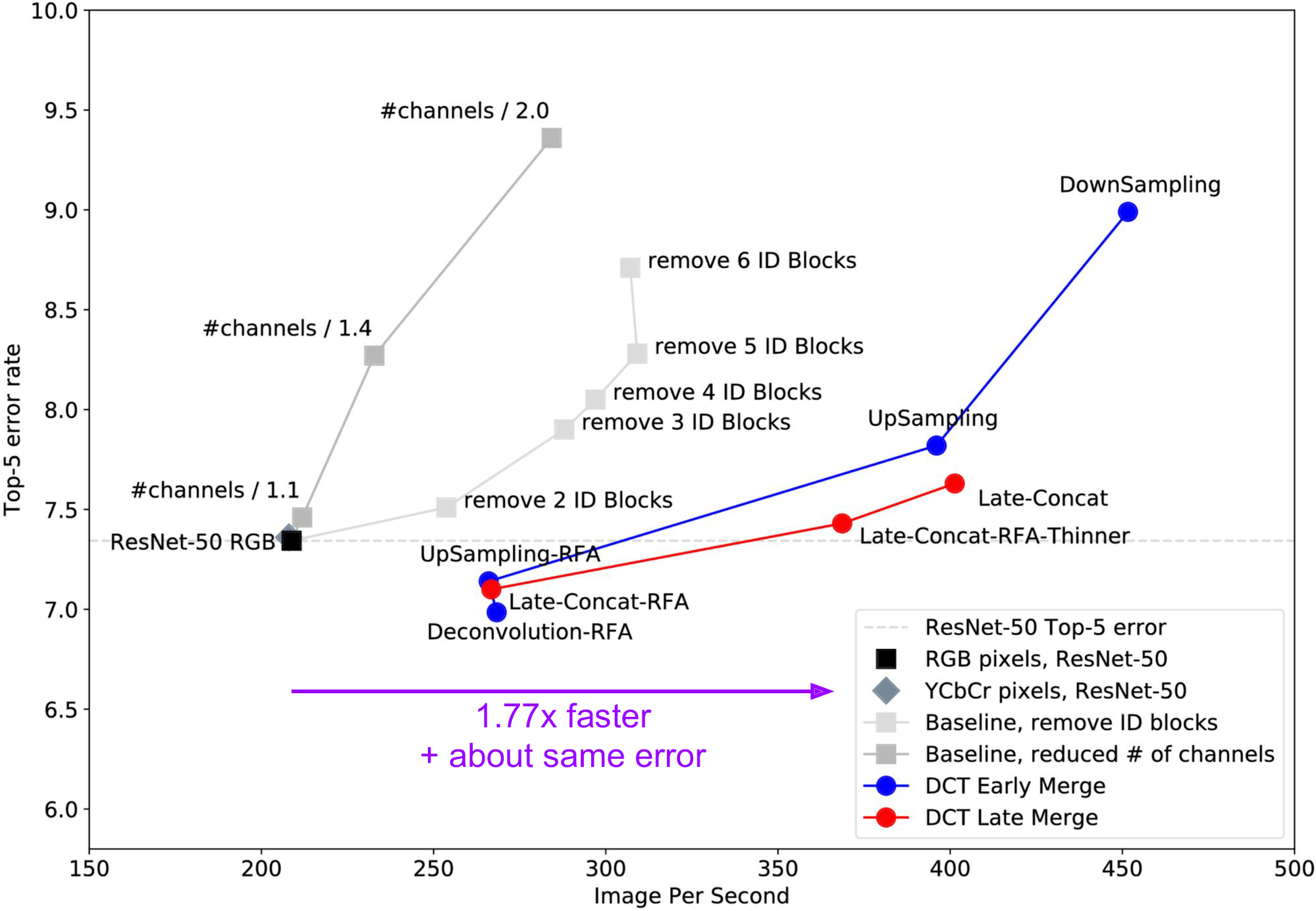
Late-Concat-RFA:receptive field aware version;
Late-Concat-RFA-Thinner:通过使用更少过滤器而调整速度的版本。加速1.77倍,错误率相近。
结论:帕累托前沿再次前移。
Discussion
有趣的是,颜色信息在网络后期(当它与从亮度中学到的更高层次的概念相结合时)才被需要。在这一点上猜测可能是学习中级概念(例如:草或狗毛)需要在其与空间上不那么精确的颜色信息(例如:绿色或棕色)结合之前,精细的亮度边缘进行了好几层处理变成纹理。可以从ResNet-50从RGB像素学习到的更高频率的黑白边缘和更低频率(或常数)的颜色检测器中预期这个结果。

许多边缘检测器基本上都是黑白的,在亮度空间中操作。许多颜色特征要么在空间上是恒定的,要么在频率上是较低的,它们可能只是用来将粗略的颜色信息传递给需要它的更高层次。我们从2012年就看到过这样的滤波器;我们是否应该期望直到网络后期才需要颜色?
速度与准确率:速度的提升是由于输入层和后续层上的数据量较小。准确率提升的主要原因是 DCT 表示的具体使用,结果对图像分类非常有效。只需将 ResNet-50 的第一个卷积层替换为stride为 8 的DCT 变换,即可获得更好的性能。它甚至比完全相同形状的学习得到的变换(learned transform)效果更好。使用更大的感受野和stride(8)表现更好,而硬编码第一层比学习得到第一层效果更好。残差网络在 2015 年得到 ImageNet 上最先进的性能,只需用DCT 替换第一层,就会进一步提高SOTA。